How exactly do indexes make data retrieval faster? What execution path does PostgreSQL follows internally? What does Postgres read from disk when an index is used? How does PostgreSQL locates a single row on the disk among millions of tuples?
To better visualize the internals, the following diagram shows the complete execution path PostgreSQL follows internally, from SQL query parsing, B-Tree traversal, Tuple Identifier (TID) lookup, heap page fetch, and finally the disk read that retrieves the actual row.
At the end of the day, PostgreSQL is still just reading and traversing files on disk.
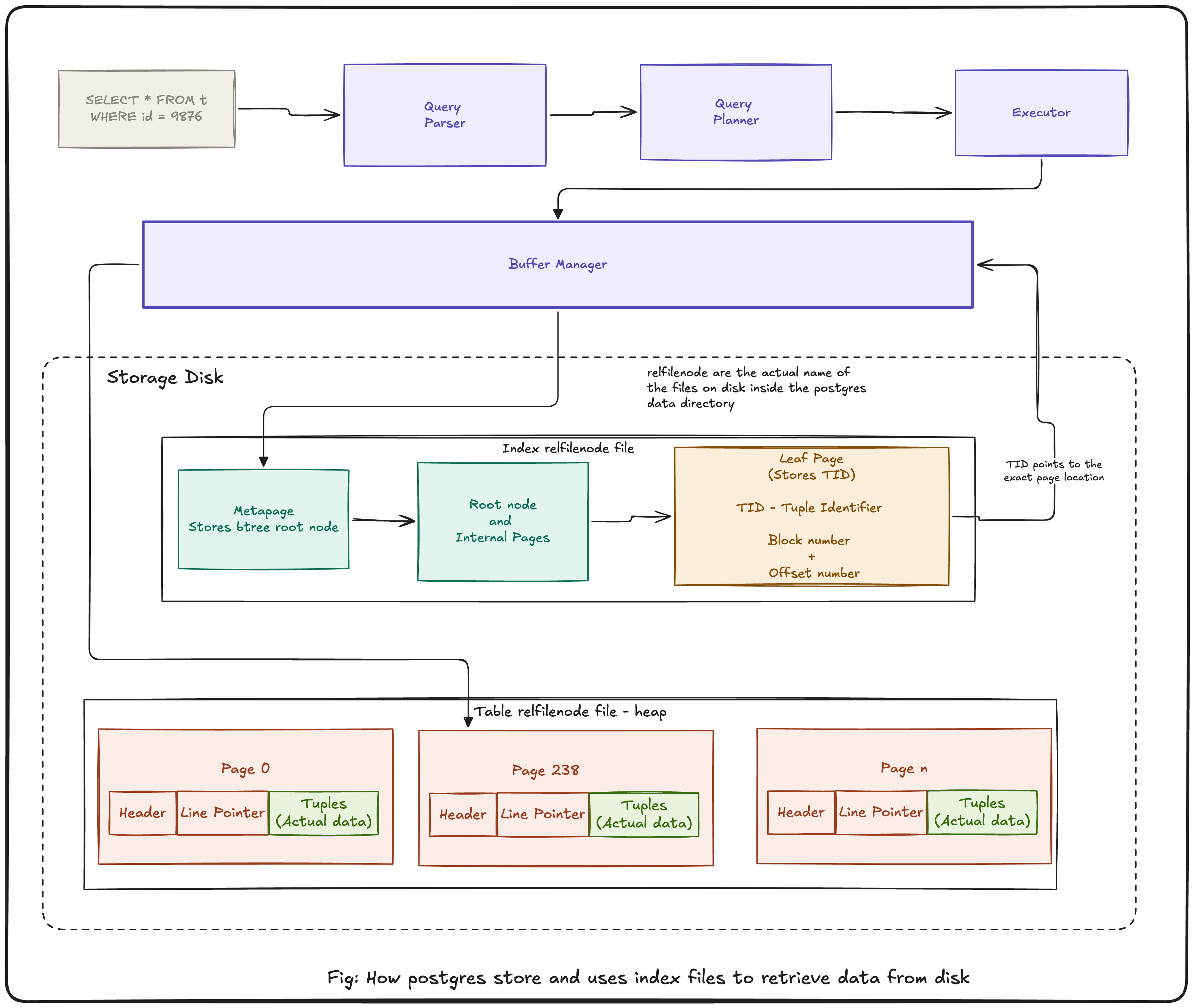
Note: The above diagram intentionally abstracts many internal PostgreSQL implementation details to focus on the high level execution path from SQL query to disk read.
So I wanted to trace the entire execution path behind a simple query like:
SELECT * FROM t WHERE id = 8972;
How does Postgres use the index on id to locate that single row from millions of records stored on disk?
This article traces how B-Tree indexes are stored on disk, how PostgreSQL traverses them to locate tuple identifiers, and how heap page lookups eventually turn into disk reads.
What are indexes?
In Postgres the index is simply another file stored on disk.
Just like tables, indexes have their own object identifier (OID) and a relfilenode
The relfilenode maps to the actual physical file storing the index data internally
The index file itself is divided into fixed size pages (or blocks). These pages collectively form the B-Tree structure used by the PostgreSQL for efficient lookups.
To make it easier to visualize, I created a domains table and traced how PostgreSQL maps both table data and it’s index to their underlying relfilenode on the disk
testdb=# \d domains
Table "public.domains"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+-------------------
id | uuid | | not null | gen_random_uuid()
url | text | | |
score | integer | | |
Indexes:
"domains_pkey" PRIMARY KEY, btree (id)
If we inspect the description of the domains table we can see that both the table and it’s index is mapped to their respective relfilenode values:
testdb=# select oid, relname, relfilenode from pg_class where relname in ('domains', 'domains_pkey');
| oid | relname | relfilenode
-------+--------------+-------------
24577 | domains | 24577
24583 | domains_pkey | 24583
(2 rows)
This means postgreSQL has created a physical file named 24583 on disk to store the B-tree index for the domains_pkey index
The file exists under the PostgreSQL’s data directory /var/lib/postgresql/data/base/{DATABASE_OID}/{relfilenode}.
root@105a5f516a57:/var/lib/postgresql/data/base/16384# ls 24583
24583 <-- this is the actual index file created when create index command is executed
At this point, the index is no longer just an abstract database optimization structure. It is an actual file on the disk that PostgreSQL traverses during query execution.
Internal Structure of the btree index file
The index relfilenode file is internally divided into fixed size 8KB pages (also called blocks).
One important point to note here is that a B tree node in PostgreSQL is not an abstract in memory structure,
it is literally a page inside the index file on disk.
The first page in the index file is metapage. It stores the metadata about the index, including the block number of the current root page of the B-Tree. When PostgreSQL needs to search for a key, traversal begins from this root page.
Each page stores hundreds of index keys in sorted order and also maintains a high key, an upper bound use by PostgreSQL to determine whether the key exists in the current page or whether traversal should continue.
# This is how one page (also called block) inside a index relfilenode file looks like
Block 5031 ********************************************************
<Header> -----
Block Offset: 0x0274e000 Offsets: Lower 612 (0x0264)
Block: Size 8192 Version 4 Upper 4648 (0x1228)
LSN: logid 0 recoff 0x0d568198 Special 8176 (0x1ff0)
Items: 147 Free Space: 4036
Checksum: 0x0000 Prune XID: 0x00000000 Flags: 0x0000 ()
Length (including item array): 612
<Data> -----
Item 1 -- Length: 24 Offset: 8152 (0x1fd8) Flags: NORMAL
Item 2 -- Length: 24 Offset: 8128 (0x1fc0) Flags: NORMAL
Item 3 -- Length: 24 Offset: 8104 (0x1fa8) Flags: NORMAL
Item 4 -- Length: 24 Offset: 8080 (0x1f90) Flags: NORMAL
Item 5 -- Length: 24 Offset: 8056 (0x1f78) Flags: NORMAL
.
.
.
Item 142 -- Length: 24 Offset: 4768 (0x12a0) Flags: NORMAL
Item 143 -- Length: 24 Offset: 4744 (0x1288) Flags: NORMAL
Item 144 -- Length: 24 Offset: 4720 (0x1270) Flags: NORMAL
Item 145 -- Length: 24 Offset: 4696 (0x1258) Flags: NORMAL
Item 146 -- Length: 24 Offset: 4672 (0x1240) Flags: NORMAL
Item 147 -- Length: 24 Offset: 4648 (0x1228) Flags: NORMAL
<Special Section> -----
BTree Index Section:
Flags: 0x0001 (LEAF)
Blocks: Previous (1213) Next (2493) Level (0) CycleId (0)
This particular page contains 147 indexed keys. PostgreSQL traverses pages like these during index lookups, progressively narrowing the search space until it reaches the leaf page containing the requested key.
Based on the comparison result, PostgreSQL follows the appropriate child page and repeats the process recursively until a leaf page is reached. PostgreSQL continuously narrows the search space from the root page down to a single leaf page. This is what makes the data retrieval faster and efficient.
How leaf node helps locating tuple
Once PostgreSQL reaches the leaf page and finds the matching index key, it retrieves the Tuple Identifier (TID)
The TID contains:
- the heap page (block) number inside the table data file
- the offset number identifying the tuple’s slot within that page
One important detail here is that the index itself does not store the actual row data.
The index only stores references pointing to where the tuple physically exists inside the heap table file.
Using the TID, PostgreSQL now knows the exact heap page and tuple offset containing the requested row.
The executor then requests buffer manager to fetch that heap page. The buffer manager first checks if the requested page already exists in the PostgreSQL shared buffers (memory cache). If the page is not present in memory, the buffer manager performs a disk read to load the heap page from the disk into memory.
Once the heap page is available, PostgreSQL follows the line pointer offset, locates the tuple, and finally returns the requested row.
Closing thoughts
A simple select query
might look trivial at the SQL layer.
But internally, PostgreSQL performs a sequence of carefully optimized operations:
- traversing B-tree pages
- locating Tuple Identifier (TID)
- fetching heap pages through buffer manager
- and finally reading data from disk when required
At the end of the day, indexes are not magic.
They are carefully crafted on-disk data structures that helps PostgreSQL narrow down the search space from millions of rows to single heap page containing requested tuple.
Understanding this execution path changes how we think about indexes, query plans, heap fetches, and database performance as a whole.
Once you realize that every query eventually becomes page traversal and disk access, PostgreSQL internals start making much more sense.